FactoredDecPOMDPDiscrete is implements a factored DecPOMDPDiscrete. More...
#include <FactoredDecPOMDPDiscrete.h>
Public Member Functions | |
| virtual void | CacheFlatModels (bool sparse) |
| void | CacheFlatRewardModel (bool sparse=false) |
| void | ClipRewardModel (Index sf, bool sparse) |
| Adjusts the reward model by ignoring a state factor. More... | |
| virtual FactoredDecPOMDPDiscrete * | Clone () const |
| Returns a pointer to a copy of this class. More... | |
| virtual double | ComputeObservationProb (Index o, Index oVal, const std::vector< Index > &As, const std::vector< Index > &Ys, const std::vector< Index > &Os) const |
| virtual double | ComputeTransitionProb (Index y, Index yVal, const std::vector< Index > &Xs, const std::vector< Index > &As, const std::vector< Index > &Ys) const |
| void | ConvertFiniteToInfiniteHorizon (size_t horizon) |
| void | CreateNewRewardModel () |
| Creates a new reward model mapping. More... | |
| void | CreateNewRewardModelForAgent (Globals::Index) |
| virtual void | ExportSpuddFile (const std::string &filename) const |
| Export fully-observable subset of this FactoredDecPOMDPDiscrete to spudd file. More... | |
| FactoredDecPOMDPDiscrete (std::string name="received unspec. by FactoredDecPOMDPDiscrete", std::string descr="received unspec. by FactoredDecPOMDPDiscrete", std::string pf="received unspec. by FactoredDecPOMDPDiscrete") | |
| Default constructor. More... | |
| const Scope & | GetAgentScopeForLRF (Index LRF) const |
| Get all the agents in the scope of an LRF. More... | |
| const FactoredQFunctionScopeForStage | GetImmediateRewardScopes () const |
| Returns all scopes of the immediate reward function in one object. More... | |
| RewardModel * | GetLRF (Index LRF) const |
| Returns a pointer to the LRF-th reward model component. More... | |
| double | GetLRFReward (Index LRF, Index sI_e, Index jaI_e) const |
| Returns reward for LRF, given ja_e - the joint index for a group action for the subset of agents as specified by the agent scope of LRF. More... | |
| double | GetLRFReward (Index LRF, const std::vector< Index > &sI_e, const std::vector< Index > &jaI_e) const |
| double | GetLRFRewardFlat (Index LRF, Index flat_s, Index full_ja) const |
| might be necessary? Returns reward for LRF, given a flat state index, and a full joint action. More... | |
| double | GetLRFRewardFlat (Index lrf, const std::vector< Index > &sfacs, const std::vector< Index > &as) const |
| size_t | GetNrAIs (Index LRF) const |
| Get the number of action instantiations. I. More... | |
| size_t | GetNrLRFs () const |
| Get the number of LRFs in the factored representation. More... | |
| size_t | GetNrXIs (Index LRF) const |
| Get the number of X instantiations for LRF. More... | |
| double | GetReward (const std::vector< Index > &sIs, const std::vector< Index > &aIs) const |
| double | GetReward (Index sI, Index jaI) const |
| Return the reward for state, joint action indices. More... | |
| double | GetReward (State *s, JointAction *ja) const |
| Function that returns the reward for a state and joint action. More... | |
| double | GetRewardForAgent (Index agentI, Index sI, Index jaI) const |
| Return the reward for state, joint action indices. More... | |
| double | GetRewardForAgent (Index agI, State *s, JointAction *ja) const |
| Function that returns the reward for a state and joint action. More... | |
| RGet * | GetRGet () const |
| const Scope & | GetStateFactorScopeForLRF (Index LRF) const |
| Get all the state factors in the scope of an LRF. More... | |
| void | InitializeInstantiationInformation () |
| Initializes some meta information computed from the scopes. More... | |
| void | InitializeStorage () |
| makes sure that _m_sfScopes, _m_agScopes, _m_LRFs are set to proper size More... | |
| void | MarginalizeISD (Index sf, std::vector< size_t > &factor_sizes, const FactoredStateDistribution *fsd) |
| Marginalizes the ISD over a given state factor. More... | |
| void | MarginalizeStateFactor (Index sf, bool sparse) |
| Attempts to remove an extraneous state factor from the problem. More... | |
| void | Print () const |
| Index | RestrictedActionVectorToJointIndex (Index LRF, const std::vector< Index > &actionVec_e) const |
| convert an action vector of restricted scope to a joint index a_e. More... | |
| Index | RestrictedStateVectorToJointIndex (Index LRF, const std::vector< Index > &stateVec_e) const |
| Get the vector of Factor indices corresponding to stateI. More... | |
| void | SetNrLRFs (size_t nr) |
| virtual void | SetOScopes () |
| void | SetReward (Index sI, Index jaI, double r) |
| Set the reward for state, joint action indices. More... | |
| void | SetReward (Index sI, Index jaI, Index sucSI, double r) |
| Set the reward for state, joint action , suc. state indices. More... | |
| void | SetReward (Index sI, Index jaI, Index sucSI, Index joI, double r) |
| Set the reward for state, joint action, suc.state, joint obs indices. More... | |
| void | SetReward (State *s, JointAction *ja, double r) |
| Function that sets the reward for a state and joint action. More... | |
| void | SetRewardForAgent (Index agentI, Index sI, Index jaI, double r) |
| void | SetRewardForAgent (Index agentI, Index sI, Index jaI, Index sucSI, double r) |
| Set the reward for state, joint action , suc. state indices. More... | |
| void | SetRewardForAgent (Index agentI, Index sI, Index jaI, Index sucSI, Index joI, double r) |
| Set the reward for state, joint action, suc.state, joint obs indices. More... | |
| void | SetRewardForAgent (Index agI, State *s, JointAction *ja, double r) |
| Function that sets the reward for an agent, state and joint action. More... | |
| void | SetRewardForLRF (Index LRF, const std::vector< Index > &Xs, const std::vector< Index > &As, double reward) |
| Set reward. More... | |
| void | SetRewardForLRF (Index LRF, const std::vector< Index > &Xs, const std::vector< Index > &As, const Scope &Y, const std::vector< Index > &Ys, const Scope &O, const std::vector< Index > &Os, double reward) |
| Set reward. More... | |
| void | SetRewardForLRF (Index LRF, const Scope &X, const std::vector< Index > &Xs, const Scope &A, const std::vector< Index > &As, const Scope &Y, const std::vector< Index > &Ys, const Scope &O, const std::vector< Index > &Os, double reward) |
| Set Reward. More... | |
| void | SetRM (Index LRF, RewardModel *rm) |
| Add the LRF-th reward model. More... | |
| void | SetScopeForLRF (Index LRF, const Scope &X, const Scope &A) |
| Sets the scope for LRF. More... | |
| void | SetScopeForLRF (Index LRF, const Scope &X, const Scope &A, const Scope &Y, const Scope &O) |
| Sets the scope for LRF. More... | |
| virtual void | SetYScopes () |
| virtual std::string | SoftPrint () const |
| Prints some information on the MultiAgentDecisionProcessDiscreteInterface. More... | |
| virtual | ~FactoredDecPOMDPDiscrete () |
| Destructor. More... | |
 Public Member Functions inherited from FactoredDecPOMDPDiscreteInterface Public Member Functions inherited from FactoredDecPOMDPDiscreteInterface | |
| virtual | ~FactoredDecPOMDPDiscreteInterface () |
| (default) Constructor More... | |
| Public Member Functions inherited from DecPOMDPDiscreteInterface | |
| virtual | ~DecPOMDPDiscreteInterface () |
| import the GetReward function from the base class in current scope. More... | |
| Public Member Functions inherited from DecPOMDPInterface | |
| virtual | ~DecPOMDPInterface () |
| Virtual destructor. More... | |
| Public Member Functions inherited from POSGInterface | |
| virtual | ~POSGInterface () |
| Virtual destructor. More... | |
| Public Member Functions inherited from MultiAgentDecisionProcessInterface | |
| virtual | ~MultiAgentDecisionProcessInterface () |
| Destructor. More... | |
| Public Member Functions inherited from MultiAgentDecisionProcessDiscreteInterface | |
| virtual | ~MultiAgentDecisionProcessDiscreteInterface () |
| Destructor. More... | |
| Public Member Functions inherited from MultiAgentDecisionProcessDiscreteFactoredStatesInterface | |
| std::string | SoftPrintState (Index sI) const |
| SoftPrints information on the MultiAgentDecisionProcessDiscrete. More... | |
| virtual | ~MultiAgentDecisionProcessDiscreteFactoredStatesInterface () |
| (default) Constructor More... | |
| Public Member Functions inherited from MultiAgentDecisionProcessDiscreteFactoredStates | |
| void | AddAction (Index AI, const std::string &name, const std::string &description="") |
| void | AddObservation (Index AI, const std::string &name, const std::string &description="") |
| Index | AddStateFactor (const std::string &n="undef. name", const std::string &d="undef. descr.") |
| Index | AddStateFactorValue (Index sf, const std::string &v="undef") |
| Scope | AgentScopeBackup (const Scope &stateScope, const Scope &agentScope) const |
| void | CacheFlatObservationModel (bool sparse=false) |
| void | CacheFlatTransitionModel (bool sparse=false) |
| size_t | ConstructJointActions () |
| size_t | ConstructJointObservations () |
| void | CreateNewObservationModel () |
| Creates a new observation model mapping: initializes new CPDs. More... | |
| void | CreateNewTransitionModel () |
| Creates a new transition model: initializes new CPDs for the 2BDN. More... | |
| Index | FactorValueIndicesToStateIndex (const std::vector< Index > &fv) const |
| convert std::vector of (indices of) factor values to (flat) state index. More... | |
| Index | FactorValueIndicesToStateIndex (const std::vector< Index > &s_e_vec, const Scope &sfSC) const |
| convert an local state vector s_e_vec of scope sfScope to a joint index. More... | |
| const TwoStageDynamicBayesianNetwork * | Get2DBN () const |
| Copy assignment operator. More... | |
| const Action * | GetAction (Index agentI, Index a) const |
| Return a ref to the a-th action of agent agentI. More... | |
| const Scope & | GetAllStateFactorScope () const |
| Convenience function to quickly get the full state scope. More... | |
| const Scope & | GetASoI_O (Index o) const |
| const Scope & | GetASoI_Y (Index y) const |
| bool | GetEventObservability () const |
| Are we using an event observation model? More... | |
| const FactoredStateDistribution * | GetFactoredISD () const |
| double | GetInitialStateProbability (Index sI) const |
| StateDistribution * | GetISD () const |
| Returns the complete initial state distribution. More... | |
| const JointAction * | GetJointAction (Index i) const |
| Return a ref to the i-th joint action. More... | |
| const JointObservation * | GetJointObservation (Index i) const |
| Return a ref to the i-th joint observation. More... | |
| const std::vector< size_t > & | GetNrActions () const |
| Return the number of actions vector. More... | |
| size_t | GetNrActions (Index AgentI) const |
| Return the number of actions of agent agentI. More... | |
| size_t | GetNrJointActions () const |
| Return the number of joint actions. More... | |
| size_t | GetNrJointActions (const Scope &agScope) const |
| Get the number of joint actions the agents in agScope can form. More... | |
| size_t | GetNrJointObservations () const |
| Return the number of joint observations. More... | |
| const std::vector< size_t > & | GetNrObservations () const |
| Return the number of observations vector. More... | |
| size_t | GetNrObservations (Index AgentI) const |
| Return the number of observations of agent agentI. More... | |
| size_t | GetNrStateFactorInstantiations (const Scope &sfScope) const |
| Get the number of joint instantiations for the factors in sfScope. More... | |
| size_t | GetNrStateFactors () const |
| Get the number of state components. -no is inherited from. More... | |
| size_t | GetNrStates () const |
| Return the number of states. More... | |
| const size_t | GetNrValuesForFactor (Index sf) const |
| Get the number of possible values for a particular factor. More... | |
| const std::vector< size_t > & | GetNrValuesPerFactor () const |
| Get the number of possible assignments or values to each factor. More... | |
| const Observation * | GetObservation (Index agentI, Index a) const |
| Return a ref to the a-th observation of agent agentI. More... | |
| const ObservationModelDiscrete * | GetObservationModelDiscretePtr () const |
| Returns a pointer to the underlying observation model. More... | |
| double | GetObservationProbability (Index jaI, Index sucSI, Index joI) const |
| Return the probability of joint observation joI: P(joI|jaI,sucSI). More... | |
| double | GetObservationProbability (Index sI, Index jaI, Index sucSI, Index joI) const |
| O(s,ja,s',jo) version. You can access a standard O(ja,s',jo) model both ways (the PS index is simply ignored in the latter case). More... | |
| OGet * | GetOGet () const |
| const Scope & | GetOSoI_O (Index o) const |
| const State * | GetState (Index i) const |
| Returns a pointer to state i. More... | |
| const StateFactorDiscrete * | GetStateFactorDiscrete (Index sfacI) const |
| TGet * | GetTGet () const |
| const TransitionModelDiscrete * | GetTransitionModelDiscretePtr () const |
| Returns a pointer to the underlying transition model. More... | |
| double | GetTransitionProbability (Index sI, Index jaI, Index sucSI) const |
| Return the probability of successor state sucSI: P(sucSI|sI,jaI). More... | |
| const Scope & | GetXSoI_O (Index o) const |
| const Scope & | GetXSoI_Y (Index y) const |
| double | GetYOProbability (const Scope &X, const std::vector< Index > &Xs, const Scope &A, const std::vector< Index > &As, const Scope &Y, const std::vector< Index > &Ys, const Scope &O, const std::vector< Index > &Os) const |
| const Scope & | GetYSoI_O (Index o) const |
| const Scope & | GetYSoI_Y (Index y) const |
| Index | IndividualToJointActionIndices (const Index *AI_ar) const |
| Returns the joint action index that corresponds to the array of specified individual action indices. More... | |
| Index | IndividualToJointActionIndices (const std::vector< Index > &indivActionIndices) const |
| Returns the joint action index that corresponds to the vector of specified individual action indices. More... | |
| Index | IndividualToJointActionIndices (const std::vector< Index > &ja_e, const Scope &agSC) const |
| indiv->joint for a restricted set (Scope) of agents More... | |
| Index | IndividualToJointObservationIndices (const std::vector< Index > &indivObservationIndices) const |
| Returns the joint observation index that corresponds to the vector of specified individual observation indices. More... | |
| Index | IndividualToJointObservationIndices (const std::vector< Index > &jo_e, const Scope &agSC) const |
| indiv->joint for a restricted set (Scope) of agents More... | |
| virtual void | Initialize2DBN () |
| virtual void | Initialize2DBN (ScopeFunctor &SetScopes, TransitionProbFunctor &ComputeTransitionProb, ObservationProbFunctor &ComputeObservationProb) |
| This signature allows us to initialize the 2DBN using externally supplied functors to set the scopes, and compute transition and observation probabilities in a discrete factored model. More... | |
| bool | JointAIndicesValid () const |
| bool | JointIndicesValid () const |
| bool | JointOIndicesValid () const |
| const std::vector< Index > & | JointToIndividualActionIndices (Index jaI) const |
| Returns a vector of indices to indiv. More... | |
| std::vector< Index > | JointToIndividualActionIndices (Index ja_e, const Scope &agSC) const |
| joint->indiv for a restricted set (Scope) of agents More... | |
| const std::vector< Index > & | JointToIndividualObservationIndices (Index joI) const |
| Returns a vector of indices to indiv. More... | |
| std::vector< Index > | JointToIndividualObservationIndices (Index jo_e, const Scope &agSC) const |
| joint->indiv for a restricted set (Scope) of agents More... | |
| Index | JointToRestrictedJointActionIndex (Index jaI, const Scope &agSc_e) const |
| Converts a global joint action index jaI to a restricted joint action index ja_e, for agents scope agSc_e Returns a vector of indices to indiv. More... | |
| Index | JointToRestrictedJointObservationIndex (Index joI, const Scope &agSc_e) const |
| Converts a global joint observation index joI to a restricted joint observation index jo_e, for agents scope agSc_e Returns a vector of indices to indiv. More... | |
| void | MarginalizeTransitionObservationModel (const Index sf, bool sparse) |
| This function marginalizes a state factor out of the flat joint transition and observation models of the system. More... | |
| MultiAgentDecisionProcessDiscreteFactoredStates (const std::string &name="received unspec. by MultiAgentDecisionProcessDiscreteFactoredStates", const std::string &descr="received unspec. by MultiAgentDecisionProcessDiscreteFactoredStates", const std::string &pf="received unspec. by MultiAgentDecisionProcessDiscreteFactoredStates") | |
| (default) Constructor More... | |
| MultiAgentDecisionProcessDiscreteFactoredStates (const MultiAgentDecisionProcessDiscreteFactoredStates &a) | |
| Copy constructor. More... | |
| MultiAgentDecisionProcessDiscreteFactoredStates & | operator= (const MultiAgentDecisionProcessDiscreteFactoredStates &o) |
| Copy assignment operator. More... | |
| void | RemoveStateFactor (Index sf) |
| This function removes a state factor from the model's MADPComponentFactoredStates, fixes the factor indices, and adjusts the 2DBN accordingly - all CPTs of nodes which depend on the removed state factor are recalculated by marginalizing their respective clique joints. More... | |
| Index | SampleInitialState () const |
| Sample a state according to the initial state PDF. More... | |
| void | SampleInitialState (std::vector< Index > &sIs) const |
| Index | SampleJointObservation (Index jaI, Index sucI) const |
| Sample an observation - needed for simulations. More... | |
| Index | SampleJointObservation (Index sI, Index jaI, Index sucI) const |
| void | SampleJointObservation (const std::vector< Index > &aIs, const std::vector< Index > &sucIs, std::vector< Index > &oIs) const |
| void | SampleJointObservation (const std::vector< Index > &sIs, const std::vector< Index > &aIs, const std::vector< Index > &sucIs, std::vector< Index > &oIs) const |
| Index | SampleSuccessorState (Index sI, Index jaI) const |
| Sample a successor state - needed by simulations. More... | |
| void | SampleSuccessorState (const std::vector< Index > &sIs, const std::vector< Index > &aIs, std::vector< Index > &sucIs) const |
| bool | SetActionsInitialized (bool b) |
| void | SetConnectionsSpecified (bool b) |
| void | SetEventObservability (bool eventO) |
| bool | SetInitialized (bool b) |
| void | SetISD (FactoredStateDistribution *p) |
| void | SetNrActions (Index AI, size_t nrA) |
| void | SetNrObservations (Index AI, size_t nrO) |
| bool | SetObservationsInitialized (bool b) |
| void | SetSoI_O (Index o, const Scope &ASoI, const Scope &YSoI, const Scope &OSoI) |
| void | SetSoI_O (Index o, const Scope &XSoI, const Scope &ASoI, const Scope &YSoI, const Scope &OSoI) |
| void | SetSoI_Y (Index y, const Scope &XSoI, const Scope &ASoI, const Scope &YSoI) |
| void | SetSparse (bool b) |
| bool | SetStatesInitialized (bool b) |
| void | SetUniformISD () |
| std::string | SoftPrint () const |
| SoftPrints information on the MultiAgentDecisionProcessDiscrete. More... | |
| std::string | SoftPrintState (Index sI) const |
| Index | StateIndexToFactorValueIndex (Index factor, Index s) const |
| Get the value of a particular state factor given a joint flat state. More... | |
| std::vector< Index > | StateIndexToFactorValueIndices (Index stateI) const |
| Get the vector of FactorValue indices corresponding to stateI used to be called virtual vector<Index> GetStateFactorValues(Index stateI) const. More... | |
| std::vector< Index > | StateIndexToFactorValueIndices (Index s_e, const Scope &sfSC) const |
| convert an local state index s_e to a vector of state factors (with scope sfScope). More... | |
| Scope | StateScopeBackup (const Scope &stateScope, const Scope &agentScope) const |
| ~MultiAgentDecisionProcessDiscreteFactoredStates () | |
| Destructor. More... | |
| Public Member Functions inherited from MultiAgentDecisionProcess | |
| void | AddAgent (std::string name) |
| Add a new agent with name "name" to the MADP. More... | |
| Index | GetAgentIndexByName (const std::string &s) const |
| Returns the index of an agent given its name, if it exists. More... | |
| std::string | GetAgentNameByIndex (Index i) const |
| Returns the name of the agent at the given index. More... | |
| const Scope & | GetAllAgentScope () const |
| std::string | GetDescription () const |
| std::string | GetName () const |
| size_t | GetNrAgents () const |
| Returns the number of agents in this MultiAgentDecisionProcess. More... | |
| std::string | GetProblemFile () const |
| Returns the name of the problem file. More... | |
| std::string | GetUnixName () const |
| Returns a name which can be in unix path, by default the base part of the problem filename. More... | |
| MultiAgentDecisionProcess (size_t nrAgents, const std::string &name="received unspec. by MultiAgentDecisionProcess", const std::string &description="received unspec. by MultiAgentDecisionProcess", const std::string &pf="received unspec. by MultiAgentDecisionProcess") | |
| Constructor. More... | |
| MultiAgentDecisionProcess (const std::string &name="received unspec. by MultiAgentDecisionProcess", const std::string &description="received unspec. by MultiAgentDecisionProcess", const std::string &pf="received unspec. by MultiAgentDecisionProcess") | |
| Default Constructor without specifying the number of agents. More... | |
| void | Print () const |
| void | SetDescription (const std::string &description) |
| void | SetName (const std::string &name) |
| void | SetNrAgents (size_t nrAgents) |
| Sets the number of agents. More... | |
| void | SetUnixName (std::string unixName) |
| Sets the name which can be used inin unix paths. More... | |
| std::string | SoftPrint () const |
| Prints some information on the MultiAgentDecisionProcess. More... | |
| virtual | ~MultiAgentDecisionProcess () |
| Destructor. More... | |
| Public Member Functions inherited from DecPOMDP | |
| DecPOMDP () | |
| Default constructor. sets RewardType to REWARD and discount to 1.0. More... | |
| double | GetDiscount () const |
| Returns the discount parameter. More... | |
| double | GetDiscountForAgent (Index agentI) const |
| Returns the discount parameter. More... | |
| reward_t | GetRewardType () const |
| Returns the reward type. More... | |
| reward_t | GetRewardTypeForAgent (Index agentI) const |
| Returns the reward type. More... | |
| void | SetDiscount (double d) |
| Sets the discount parameter to d. More... | |
| void | SetDiscountForAgent (Index agentI, double d) |
| Functions needed for POSGInterface: More... | |
| void | SetRewardType (reward_t r) |
| Sets the reward type to reward_t r. More... | |
| void | SetRewardTypeForAgent (Index agentI, reward_t r) |
| Sets the reward type to reward_t r. More... | |
| std::string | SoftPrint () const |
| SoftPrints some information on the DecPOMDP. More... | |
Static Protected Member Functions | |
| static bool | ConsistentVectorsOnSpecifiedScopes (const std::vector< Index > &v1, const Scope &scope1, const std::vector< Index > &v2, const Scope &scope2) |
| Auxiliary function that returns whether v1 is consistent with v2. More... | |
Private Attributes | |
| std::vector< Scope > | _m_agScopes |
| bool | _m_cached_FlatRM |
| FactoredQFunctionScopeForStage | _m_immRewScope |
| GetImmediateRewardScopes returns a reference to the following: More... | |
| std::vector< RewardModel * > | _m_LRFs |
| std::vector< std::vector < size_t > > | _m_nrActionVals |
| For each LRF, we maintain the nr of actions for each agent in its scope. More... | |
| std::vector< size_t > | _m_nrAIs |
| for each LRF we maintain the nr of action instantiations More... | |
| size_t | _m_nrLRFs |
| std::vector< std::vector < size_t > > | _m_nrSFVals |
| We maintain the nr of values for each state factor in the scope of lrf. More... | |
| std::vector< size_t > | _m_nrXIs |
| for each LRF we maintain the nr of X instantiations More... | |
| RewardModel * | _m_p_rModel |
| Pointer to model. More... | |
| std::vector< Scope > | _m_sfScopes |
| bool | _m_sparse_FlatRM |
Additional Inherited Members | |
| Protected Member Functions inherited from MultiAgentDecisionProcessDiscreteFactoredStates | |
| TwoStageDynamicBayesianNetwork * | Get2DBN () |
| virtual bool | SanityCheckObservations () const |
| virtual bool | SanityCheckTransitions () const |
| Protected Attributes inherited from MultiAgentDecisionProcess | |
| std::vector< Agent > | _m_agents |
| Vector containing Agent objects, which are indexed named entities. More... | |
| Scope | _m_allAgentsScope |
| Scope containing all agents - usefull sometimes. More... | |
| size_t | _m_nrAgents |
| The number of agents participating in the MADP. More... | |
| std::string | _m_problemFile |
| String holding the filename of the problem file to be parsed - if applicable. More... | |
| std::string | _m_unixName |
| String for the unix name of the MADP. More... | |
Detailed Description
FactoredDecPOMDPDiscrete is implements a factored DecPOMDPDiscrete.
This class implements FactoredDecPOMDPDiscreteInterface is the interface for a Dec-POMDP with factored states. It defines the get/set reward functions.
This implementation maintains a vector of Local reward functions (LRFs), each of which is a RewardModel. The implementation of each RewardModel (which subclass of RewardModel is actually used) can differ per LRF.
Each reward model is defined over a subset of state factors and states: the state factor and agent scope of the particular LRF. This class is responsible of all index conversions. (so the referred RewardModels do not know anything about scopes etc.)
The `edges' in this code refer to edges of the graph constructed from the factored immediate reward function. (i.e., each `edge' corresponds to a local reward function)
Constructor & Destructor Documentation
| FactoredDecPOMDPDiscrete::FactoredDecPOMDPDiscrete | ( | std::string | name = "received unspec. by FactoredDecPOMDPDiscrete", |
| std::string | descr = "received unspec. by FactoredDecPOMDPDiscrete", |
||
| std::string | pf = "received unspec. by FactoredDecPOMDPDiscrete" |
||
| ) |
Default constructor.
Constructor that sets the name, description, and problem file, and subsequently loads this problem file.
Referenced by Clone().
|
virtual |
Destructor.
References _m_LRFs, and _m_p_rModel.
Member Function Documentation
|
virtual |
Reimplemented from MultiAgentDecisionProcessDiscreteFactoredStatesInterface.
Reimplemented in FactoredMMDPDiscrete.
References MultiAgentDecisionProcessDiscreteFactoredStates::CacheFlatObservationModel(), CacheFlatRewardModel(), MultiAgentDecisionProcessDiscreteFactoredStates::CacheFlatTransitionModel(), MultiAgentDecisionProcessDiscreteFactoredStates::ConstructJointActions(), and MultiAgentDecisionProcessDiscreteFactoredStates::ConstructJointObservations().
Referenced by ArgumentUtils::GetDecPOMDPDiscreteInterfaceFromArgs(), and ArgumentUtils::GetFactoredDecPOMDPDiscreteInterfaceFromArgs().
| void FactoredDecPOMDPDiscrete::CacheFlatRewardModel | ( | bool | sparse = false | ) |
References _m_cached_FlatRM, _m_p_rModel, _m_sparse_FlatRM, MultiAgentDecisionProcessDiscreteFactoredStates::GetNrJointActions(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrStates(), GetReward(), Globals::REWARD_PRECISION, and RewardModelDiscreteInterface::Set().
Referenced by CacheFlatModels().
| void FactoredDecPOMDPDiscrete::ClipRewardModel | ( | Index | sf, |
| bool | sparse | ||
| ) |
Adjusts the reward model by ignoring a state factor.
References _m_cached_FlatRM, _m_p_rModel, _m_sparse_FlatRM, MultiAgentDecisionProcessDiscreteFactoredStates::GetNrJointActions(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrStateFactors(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrValuesForFactor(), GetReward(), Globals::REWARD_PRECISION, and RewardModelDiscreteInterface::Set().
Referenced by MarginalizeStateFactor().
|
inlinevirtual |
Returns a pointer to a copy of this class.
Implements FactoredDecPOMDPDiscreteInterface.
Reimplemented in ProblemFireFightingFactored, ProblemAloha, ProblemFOBSFireFightingFactored, and FactoredMMDPDiscrete.
References FactoredDecPOMDPDiscrete().
|
inlinevirtual |
Implements MultiAgentDecisionProcessDiscreteFactoredStates.
Reimplemented in ProblemAloha, ProblemFireFightingFactored, and FactoredMMDPDiscrete.
|
inlinevirtual |
Implements MultiAgentDecisionProcessDiscreteFactoredStates.
Reimplemented in ProblemAloha, ProblemFireFightingFactored, and ProblemFOBSFireFightingFactored.
Referenced by FactoredMMDPDiscrete::Initialize2DBN().
|
staticprotected |
Auxiliary function that returns whether v1 is consistent with v2.
The scope of v2 (scope 2) should be a subset of scope 1
References Scope::GetPositionForIndex().
Referenced by SetRewardForLRF().
|
inline |
|
inlinevirtual |
Creates a new reward model mapping.
Implements DecPOMDPDiscreteInterface.
Referenced by CreateNewRewardModelForAgent().
|
inline |
References CreateNewRewardModel().
|
virtual |
Export fully-observable subset of this FactoredDecPOMDPDiscrete to spudd file.
This function is virtual since some specific problem instances may want to override variable names or other elements to conform with the spudd file format.
References MultiAgentDecisionProcessDiscreteFactoredStates::Get2DBN(), MultiAgentDecisionProcessDiscreteFactoredStates::GetAction(), MultiAgentDecisionProcess::GetAgentNameByIndex(), GetAgentScopeForLRF(), MultiAgentDecisionProcess::GetAllAgentScope(), TwoStageDynamicBayesianNetwork::GetASoI_Y(), DecPOMDP::GetDiscount(), GetLRFReward(), NamedDescribedEntity::GetName(), MultiAgentDecisionProcess::GetName(), MultiAgentDecisionProcess::GetNrAgents(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrJointActions(), GetNrLRFs(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrStateFactors(), TwoStageDynamicBayesianNetwork::GetNrVals_XSoI_Y(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrValuesForFactor(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrValuesPerFactor(), MultiAgentDecisionProcessDiscreteFactoredStates::GetStateFactorDiscrete(), GetStateFactorScopeForLRF(), StateFactorDiscrete::GetStateFactorValue(), TwoStageDynamicBayesianNetwork::GetXSoI_Y(), TwoStageDynamicBayesianNetwork::GetYProbabilitiesExactScopes(), IndexTools::Increment(), MultiAgentDecisionProcessDiscreteFactoredStates::JointToIndividualActionIndices(), IndexTools::RestrictIndividualIndicesToNarrowerScope(), and IndexTools::RestrictIndividualIndicesToScope().
Get all the agents in the scope of an LRF.
Implements FactoredDecPOMDPDiscreteInterface.
Referenced by ExportSpuddFile(), GetLRFRewardFlat(), ProblemAloha::InitializeAloha(), InitializeInstantiationInformation(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
|
virtual |
Returns all scopes of the immediate reward function in one object.
Implements FactoredDecPOMDPDiscreteInterface.
References _m_agScopes, _m_nrLRFs, _m_sfScopes, and FactoredQFunctionScopeForStage::AddLocalQ().
|
inlinevirtual |
Returns a pointer to the LRF-th reward model component.
Implements FactoredDecPOMDPDiscreteInterface.
|
inlinevirtual |
Returns reward for LRF, given ja_e - the joint index for a group action for the subset of agents as specified by the agent scope of LRF.
s_e - the (joint) index of the subset of factors specified by the state factor scope of LRF.
For instance, let the agents scope of LRF be <1,3>, then group action <3,5> means that agent 1 select action 3, while agent 3 performs its 5th action. Using indextools we can find agSc_jaI. E.g. agSc_jaI = IndividualToJointIndices( <3,5>, <6,6> ) (where <6,6> is a vector which specifies the number of actions per agent, see IndexTools.h for more info).
Implements FactoredDecPOMDPDiscreteInterface.
Referenced by ExportSpuddFile(), GetLRFReward(), GetLRFRewardFlat(), and SetRewardForLRF().
|
virtual |
Implements FactoredDecPOMDPDiscreteInterface.
References GetLRFReward(), RestrictedActionVectorToJointIndex(), and RestrictedStateVectorToJointIndex().
|
virtual |
might be necessary? Returns reward for LRF, given a flat state index, and a full joint action.
Implements FactoredDecPOMDPDiscreteInterface.
References MultiAgentDecisionProcessDiscreteFactoredStates::JointToIndividualActionIndices(), and MultiAgentDecisionProcessDiscreteFactoredStates::StateIndexToFactorValueIndices().
Referenced by GetReward().
| size_t FactoredDecPOMDPDiscrete::GetNrAIs | ( | Index | LRF | ) | const |
Get the number of action instantiations. I.
I.e., the number of local joint (group) actions Should be called after InitializeInstantiationInformation()
References _m_nrAIs.
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
|
inlinevirtual |
Get the number of LRFs in the factored representation.
Implements FactoredDecPOMDPDiscreteInterface.
References _m_nrLRFs.
Referenced by ExportSpuddFile(), GetReward(), and InitializeInstantiationInformation().
| size_t FactoredDecPOMDPDiscrete::GetNrXIs | ( | Index | LRF | ) | const |
Get the number of X instantiations for LRF.
Each LRF has a local state space X. This function returns the size of this local state space. Should be called after InitializeInstantiationInformation()
References _m_nrXIs.
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
|
virtual |
Implements FactoredDecPOMDPDiscreteInterface.
References GetLRFRewardFlat(), and GetNrLRFs().
Referenced by CacheFlatRewardModel(), ClipRewardModel(), GetReward(), GetRewardForAgent(), and SetReward().
Return the reward for state, joint action indices.
Implements DecPOMDPDiscreteInterface.
References _m_cached_FlatRM, _m_p_rModel, RewardModelDiscreteInterface::Get(), GetLRFRewardFlat(), and GetNrLRFs().
|
inlinevirtual |
Function that returns the reward for a state and joint action.
This should be very generic.
Implements DecPOMDPInterface.
References GetReward().
|
inline |
Return the reward for state, joint action indices.
References GetReward().
|
inlinevirtual |
Function that returns the reward for a state and joint action.
This should be very generic.
Implements POSGInterface.
References GetReward().
|
virtual |
Implements DecPOMDPDiscreteInterface.
References _m_cached_FlatRM, _m_p_rModel, and _m_sparse_FlatRM.
Get all the state factors in the scope of an LRF.
Implements FactoredDecPOMDPDiscreteInterface.
Referenced by ExportSpuddFile(), GetLRFRewardFlat(), ProblemAloha::InitializeAloha(), InitializeInstantiationInformation(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
| void FactoredDecPOMDPDiscrete::InitializeInstantiationInformation | ( | ) |
Initializes some meta information computed from the scopes.
This function computes the number of X and A instantiations, the vectors with the number of values for sfacs and step-size arrays used in conversion from individual <-> joint indices.
References _m_nrActionVals, _m_nrAIs, _m_nrSFVals, _m_nrXIs, GetAgentScopeForLRF(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrActions(), GetNrLRFs(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrValuesPerFactor(), GetStateFactorScopeForLRF(), and IndexTools::RestrictIndividualIndicesToScope().
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
| void FactoredDecPOMDPDiscrete::InitializeStorage | ( | ) |
makes sure that _m_sfScopes, _m_agScopes, _m_LRFs are set to proper size
References _m_agScopes, _m_LRFs, _m_nrActionVals, _m_nrAIs, _m_nrLRFs, _m_nrSFVals, _m_nrXIs, and _m_sfScopes.
Referenced by SetNrLRFs().
| void FactoredDecPOMDPDiscrete::MarginalizeISD | ( | Index | sf, |
| std::vector< size_t > & | factor_sizes, | ||
| const FactoredStateDistribution * | fsd | ||
| ) |
Marginalizes the ISD over a given state factor.
References MultiAgentDecisionProcessDiscreteFactoredStates::GetISD(), FactoredStateDistribution::GetProbability(), IndexTools::Increment(), Globals::PROB_PRECISION, FSDist_COF::SanityCheck(), MultiAgentDecisionProcessDiscreteFactoredStates::SetISD(), and FSDist_COF::SetProbability().
Referenced by MarginalizeStateFactor().
| void FactoredDecPOMDPDiscrete::MarginalizeStateFactor | ( | Index | sf, |
| bool | sparse | ||
| ) |
Attempts to remove an extraneous state factor from the problem.
Such state factors are typically useful when modeling large systems graphically, but hinder performance when solving with flat algorithms (such as Perseus). Currently, it only supports the marginalization of nodes without NS dependencies, and which do not directly influence any LRF
References ClipRewardModel(), MultiAgentDecisionProcessDiscreteFactoredStates::GetFactoredISD(), MultiAgentDecisionProcessDiscreteFactoredStates::GetNrValuesPerFactor(), MarginalizeISD(), and MultiAgentDecisionProcessDiscreteFactoredStates::MarginalizeTransitionObservationModel().
Referenced by ArgumentUtils::GetFactoredDecPOMDPDiscreteInterfaceFromArgs().
|
inlinevirtual |
Implements FactoredDecPOMDPDiscreteInterface.
References SoftPrint().
|
virtual |
convert an action vector of restricted scope to a joint index a_e.
This is a convenience function that performs indiv->joint action index conversion for a specific edge e (LRF). (i.e., this function is typically called when requesting the immediate reward)
- actionVec_e is an assignment of all actions in the agent scope scope of e.
- the funtion returns a joint (group) index a_e.
Implements FactoredDecPOMDPDiscreteInterface.
References _m_nrActionVals, and IndexTools::IndividualToJointIndices().
Referenced by GetLRFReward(), and SetRewardForLRF().
|
virtual |
Get the vector of Factor indices corresponding to stateI.
convert a state vector of restricted scope to a joint index s_e.
This is a convenience function that performs indiv->joint state index conversion for a specific edge e (LRF).
- stateVec_e is an assignment of all state factors in the state factor scope of e.
- the funtion returns a joint (group) index s_e.
Implements FactoredDecPOMDPDiscreteInterface.
References _m_nrSFVals, and IndexTools::IndividualToJointIndices().
Referenced by GetLRFReward(), and SetRewardForLRF().
|
inline |
References InitializeStorage().
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
|
inlinevirtual |
Implements MultiAgentDecisionProcessDiscreteFactoredStates.
Reimplemented in ProblemFireFightingFactored, ProblemAloha, FactoredMMDPDiscrete, and ProblemFireFightingGraph.
Set the reward for state, joint action indices.
Implements DecPOMDPDiscreteInterface.
Referenced by SetReward(), and SetRewardForAgent().
Set the reward for state, joint action , suc. state indices.
Implements DecPOMDPDiscreteInterface.
References GetReward(), MultiAgentDecisionProcessDiscreteFactoredStates::GetTransitionProbability(), and SetReward().
|
virtual |
Set the reward for state, joint action, suc.state, joint obs indices.
Implements DecPOMDPDiscreteInterface.
|
inlinevirtual |
Function that sets the reward for a state and joint action.
This should be very generic.
Implements DecPOMDPInterface.
References SetReward().
|
inline |
References SetReward().
|
inline |
Set the reward for state, joint action , suc. state indices.
References SetReward().
|
inline |
Set the reward for state, joint action, suc.state, joint obs indices.
References SetReward().
|
inlinevirtual |
Function that sets the reward for an agent, state and joint action.
This should be very generic.
Implements POSGInterface.
References SetReward().
| void FactoredDecPOMDPDiscrete::SetRewardForLRF | ( | Index | LRF, |
| const std::vector< Index > & | Xs, | ||
| const std::vector< Index > & | As, | ||
| double | reward | ||
| ) |
Set reward.
The reward model should already be added. This function does not require any back-projection or whatsoever.
References _m_agScopes, _m_LRFs, _m_sfScopes, RestrictedActionVectorToJointIndex(), RestrictedStateVectorToJointIndex(), and PrintTools::SoftPrintVector().
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), ProblemFireFightingFactored::InitializePFFF(), and SetRewardForLRF().
| void FactoredDecPOMDPDiscrete::SetRewardForLRF | ( | Index | LRF, |
| const std::vector< Index > & | Xs, | ||
| const std::vector< Index > & | As, | ||
| const Scope & | Y, | ||
| const std::vector< Index > & | Ys, | ||
| const Scope & | O, | ||
| const std::vector< Index > & | Os, | ||
| double | reward | ||
| ) |
Set reward.
The reward model should already be added. Because we maintain reward functions of the form R(s,a), this function distributes the reward according the the expectation of y, o. I.e., Let X, A be the registered scope for LRF, and x,a be instantiations of those scopes. Then
![\[ R(x,a) = \sum_{y,o} R(x,a,y,o) \Pr(y,o|x,a) \]](form_6.png)
Therefore this function performs
![\[ R(x,a) += R(x,a,y,o) \Pr(y,o|x,a) \]](form_7.png)
(by calling SetRewardForLRF(Index LRF, const std::vector<Index>& Xs,const std::vector<Index>& As, double reward) )
Repeatedly calling this function (for all y, o) should result in a valid R(x,a).
This means that
- Xs should be a vector of SFValue indices for registered scope _m_sfScopes[LRF].
- As should be a vector specifying an action for each agent specified by agent scope _m_agScopes[LRF].
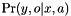 should be defined. (i.e., the scope backup of o and y should not involve variables not in X,A).
should be defined. (i.e., the scope backup of o and y should not involve variables not in X,A).
References _m_agScopes, _m_sfScopes, GetLRFReward(), MultiAgentDecisionProcessDiscreteFactoredStates::GetYOProbability(), and SetRewardForLRF().
| void FactoredDecPOMDPDiscrete::SetRewardForLRF | ( | Index | LRF, |
| const Scope & | X, | ||
| const std::vector< Index > & | Xs, | ||
| const Scope & | A, | ||
| const std::vector< Index > & | As, | ||
| const Scope & | Y, | ||
| const std::vector< Index > & | Ys, | ||
| const Scope & | O, | ||
| const std::vector< Index > & | Os, | ||
| double | reward | ||
| ) |
Set Reward.
This set reward function is best illustrated by an example of the factored firefighting problem [Oliehoek08AAMAS]. There we have that the reward function for the first house can be expressed as.
![\[ \forall_{f_1,f_2,a_1} \quad R(f_1,f_2,a_1) = \sum_{f_1'} \Pr(f_1'|f_1,f_2,a_1) R(f_1') \]](form_9.png)
That is, if the scope is underspecified (X and A only are subsets of the registered scopes) than it holds {for all} non-specified factors and actions.
This version of SetRewardForLRF should be called with
- X a subset of the registered state factor scope for LRF
- A a subset of the registered agent scope for LRF
Consequently it will call void SetRewardForLRF(Index LRF, const vector<Index>& Xs, const vector<Index>& As, const Scope& Y, const vector<Index>& Ys, const Scope& O, const vector<Index>& Os, double reward ) for all non specified state factors and actions.
References _m_agScopes, _m_nrActionVals, _m_nrSFVals, _m_sfScopes, ConsistentVectorsOnSpecifiedScopes(), IndexTools::Increment(), and SetRewardForLRF().
|
inline |
Add the LRF-th reward model.
It can already contain all rewards, or the reward model can now be filled using the SetRewardForLRF functions.
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), and ProblemFireFightingFactored::InitializePFFF().
|
inline |
Sets the scope for LRF.
It is in the desired form, so can copied directly in to _m_sfScopes and _m_agScopes.
Referenced by ProblemAloha::InitializeAloha(), ProblemFOBSFireFightingFactored::InitializePFFF(), ProblemFireFightingFactored::InitializePFFF(), and SetScopeForLRF().
| void FactoredDecPOMDPDiscrete::SetScopeForLRF | ( | Index | LRF, |
| const Scope & | X, | ||
| const Scope & | A, | ||
| const Scope & | Y, | ||
| const Scope & | O | ||
| ) |
Sets the scope for LRF.
Sets the scopes that will be used to set the reward with SetRewardForLRF().
The scopes Y and O are back-projected to obtain augmented scopes X' and A', through:
![\[ X' = X \cup \Gamma_x( Y \cup O ) \]](form_2.png)
![\[ A' = A \cup \Gamma_a( Y \cup O ) \]](form_3.png)
where 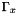 is the state factor scope backup and
is the state factor scope backup and 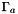 is the agent scope backup.
is the agent scope backup.
- See also
- StateScopeBackup AgentScopeBackup
References MultiAgentDecisionProcessDiscreteFactoredStates::AgentScopeBackup(), Scope::Insert(), SetScopeForLRF(), Scope::Sort(), and MultiAgentDecisionProcessDiscreteFactoredStates::StateScopeBackup().
|
inlinevirtual |
Implements MultiAgentDecisionProcessDiscreteFactoredStates.
Reimplemented in ProblemFireFightingFactored, ProblemFOBSFireFightingFactored, ProblemAloha, ProblemFireFightingGraph, and ProblemFOBSFireFightingGraph.
Referenced by FactoredMMDPDiscrete::SetScopes().
|
virtual |
Prints some information on the MultiAgentDecisionProcessDiscreteInterface.
Implements FactoredDecPOMDPDiscreteInterface.
Reimplemented in FactoredMMDPDiscrete.
References _m_agScopes, _m_LRFs, _m_nrLRFs, _m_sfScopes, DecPOMDP::SoftPrint(), and MultiAgentDecisionProcessDiscreteFactoredStates::SoftPrint().
Referenced by Print(), and FactoredMMDPDiscrete::SoftPrint().
Member Data Documentation
|
private |
Referenced by GetImmediateRewardScopes(), InitializeStorage(), SetRewardForLRF(), and SoftPrint().
|
private |
Referenced by CacheFlatRewardModel(), ClipRewardModel(), GetReward(), and GetRGet().
|
private |
GetImmediateRewardScopes returns a reference to the following:
|
private |
Referenced by InitializeStorage(), SetRewardForLRF(), SoftPrint(), and ~FactoredDecPOMDPDiscrete().
|
private |
For each LRF, we maintain the nr of actions for each agent in its scope.
Referenced by InitializeInstantiationInformation(), InitializeStorage(), RestrictedActionVectorToJointIndex(), and SetRewardForLRF().
|
private |
for each LRF we maintain the nr of action instantiations
I.e., the number of local joint actions (group actions).
Referenced by GetNrAIs(), InitializeInstantiationInformation(), and InitializeStorage().
|
private |
Referenced by GetImmediateRewardScopes(), GetNrLRFs(), InitializeStorage(), and SoftPrint().
|
private |
We maintain the nr of values for each state factor in the scope of lrf.
these vectors are used in the conversion from/to joint indices
Referenced by InitializeInstantiationInformation(), InitializeStorage(), RestrictedStateVectorToJointIndex(), and SetRewardForLRF().
|
private |
for each LRF we maintain the nr of X instantiations
I.e., the size of its local state space.
Referenced by GetNrXIs(), InitializeInstantiationInformation(), and InitializeStorage().
|
private |
Pointer to model.
Referenced by CacheFlatRewardModel(), ClipRewardModel(), GetReward(), GetRGet(), and ~FactoredDecPOMDPDiscrete().
|
private |
Referenced by GetImmediateRewardScopes(), InitializeStorage(), SetRewardForLRF(), and SoftPrint().
|
private |
Referenced by CacheFlatRewardModel(), ClipRewardModel(), and GetRGet().
